
¿Te has preguntado alguna vez cómo es que tus aplicaciones favoritas funcionan de manera rápida y eficiente, a pesar de que miles de usuarios como tú la usan al mismo tiempo?
Piensa en la última vez que compraste una entrada al cine, pediste comida por delivery o revisaste el estado de tu cuenta bancaria desde una app.

Detrás de esa experiencia se encuentra una infraestructura backend robusta y bien optimizada, diseñada para gestionar grandes volúmenes de datos y operaciones, asegurando que todo funcione sin interrupciones, incluso en los momentos de mayor actividad.
En este artículo veremos algunos conceptos y fundamentos básicos e importantes que se tiene en cuenta en el diseño de una infraestructura backend. Cada plataforma tiene sus propias necesidades y objetivos, por lo tanto su propio diseño backend.
Entonces, ¿qué es exactamente la infraestructura de backend?
En las infraestructuras modernas —especialmente en aplicaciones SaaS— ya no se piensa en un único «servidor» que lo hace todo, sino en un conjunto de componentes distribuidos donde conviven servidores de aplicación, de bases de datos, de caché, de autenticación, de colas de mensajes y otros tantos.
Entender los distintos tipos de servidores, sus propósitos y cómo interactúan entre sí es esencial para diseñar sistemas sostenibles y preparados para el crecimiento.
Imagina el backend como el motor que impulsa la funcionalidad y la seguridad de una aplicación. Mientras que el frontend es la capa visible y atractiva con la que interactúan los usuarios, el backend es el corazón de la operación, encargado de procesar datos, manejar solicitudes y asegurar que cada función en la aplicación ocurra sin fallos.
Esta infraestructura abarca desde servidores y bases de datos hasta APIs y protocolos de seguridad que protegen tanto la aplicación como a sus usuarios.
Su principal objetivo es mantener la integridad y disponibilidad de los datos, además de garantizar que las operaciones se realicen de manera eficiente. Sin una base sólida en estos aspectos, incluso la interfaz más atractiva puede volverse ineficiente o vulnerable ante el crecimiento de usuarios o ataques externos.
Además de mantener el flujo de datos, el backend tiene la tarea de asegurar la escalabilidad de una aplicación.
¿Qué sucede cuando una aplicación pasa de tener cientos de usuarios a millones? El backend debe ser lo suficientemente robusto como para manejar ese crecimiento, gestionando la carga de trabajo adicional sin comprometer el rendimiento.
Aquí entran en juego elementos clave como la arquitectura de microservicios, los sistemas de caché y la distribución eficiente de solicitudes entre servidores.
Entender esta tecnología es esencial para los desarrolladores que buscan crear aplicaciones no solo funcionales, sino también resilientes y escalables. Con una infraestructura backend bien diseñado, se puede asegurar una experiencia de usuario consistente, incluso bajo alta demanda o condiciones imprevistas.
La verdadera magia de una aplicación exitosa no radica solo en lo que el usuario ve, sino en cómo se gestiona lo que no ve.
Servidores: Pilares fundamentales de la infraestructura backend
En el corazón de una infraestructura backend moderna y escalable reside una arquitectura desacoplada. Los servidores, lejos de ser unidades monolíticas, se definen por sus responsabilidades especializadas. Esta granularidad es esencial para alcanzar niveles óptimos de eficiencia, seguridad, rendimiento y escalabilidad. A continuación, detallaremos los tipos de servidores predominantes en este paradigma avanzado.
Servidores Web
Primero, están los servidores web, encargados de gestionar las solicitudes HTTP entrantes y entregar contenido estático como HTML, CSS, JavaScript, imágenes y otros recursos. Estos servidores son la primera línea de contacto entre el navegador del usuario y la aplicación, manejando el tráfico y sirviendo los archivos necesarios para renderizar las interfaces.
Ejemplos populares incluyen Nginx, LightSpeed Web Server y Apache HTTP Server, conocidos por su capacidad para manejar grandes volúmenes de tráfico y distribuir contenido de manera eficiente.
Servidores de Aplicaciones
A continuación, tenemos los servidores de aplicaciones, responsables de ejecutar la lógica de negocio y generar contenido dinámico. Estos servidores procesan las operaciones más complejas, como cálculos, autenticación y la lógica específica de la aplicación.
Cuando un usuario interactúa con un formulario o realiza una acción que requiere procesamiento de datos, el servidor de aplicaciones se encarga de esa lógica, conectándose con las bases de datos y devolviendo la respuesta adecuada. Ejemplos típicos son Node JS, uWSGI, Apache Tomcat y Microsoft IIS, que permiten gestionar estas interacciones dinámicas de manera robusta.
Servidores de Base de Datos
Los servidores de bases de datos, los guardianes de los datos que hacen que las aplicaciones funcionen de manera fluida y segura. Estos servidores almacenan, organizan y recuperan grandes volúmenes de información, permitiendo a las aplicaciones acceder rápidamente a los datos que necesitan.
Además de gestionar consultas y transacciones, garantizan la integridad y disponibilidad de la información mediante sistemas avanzados de replicación y backups. Tecnologías como PostgreSQL, Cassandra, MySQL, MongoDB y CockroachDB son ejemplos destacados que soportan aplicaciones que requieren acceso a grandes conjuntos de datos, como plataformas de redes sociales o aplicaciones de comercio electrónico.
Servidores de Caché
Los servidores de caché son fundamentales para optimizar la experiencia del usuario al reducir drásticamente la latencia y disminuir la carga en los servidores de aplicación y bases de datos.
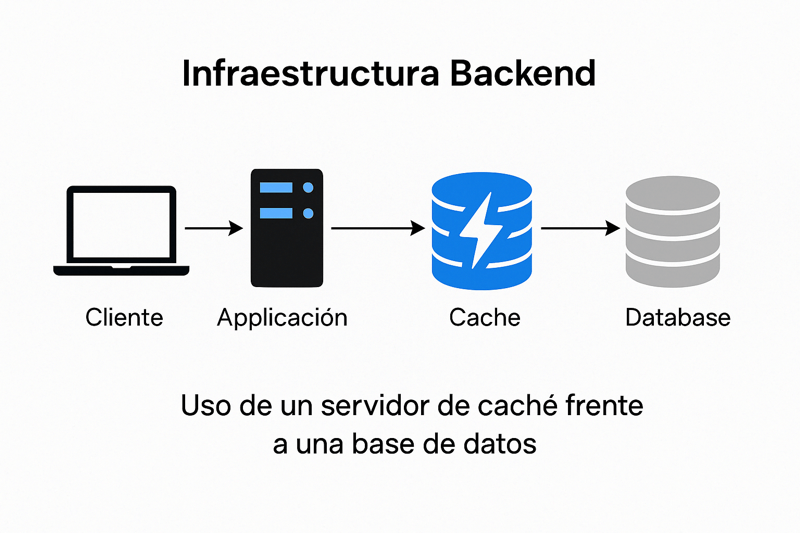
Funcionan almacenando en memoria de acceso rápido copias de datos a los que se accede con frecuencia o los resultados de consultas costosas. Cuando un cliente solicita esta información nuevamente, se sirve directamente desde la caché, evitando la necesidad de realizar la operación completa otra vez.
Imagina una página de comercio electrónico con miles de productos. Las descripciones, imágenes y precios de los productos más vistos se pueden almacenar en caché. Cuando un usuario accede a la página de un producto popular, la información se carga casi instantáneamente desde la caché en lugar de consultar la base de datos cada vez.
Tecnologías utilizadas:
- Redis: Un almacén de estructuras de datos en memoria de código abierto, utilizado como caché, broker de mensajes, cola y almacén de clave-valor. Su velocidad y versatilidad lo hacen muy popular.
- Memcached: Un sistema de almacenamiento en caché distribuido en memoria, diseñado para acelerar aplicaciones web dinámicas al aliviar la carga de la base de datos. Es simple, pero extremadamente rápido.
Servidor de colas de mensajes (Messages Brokers)
Los servidores de colas de mensajes (message brokers) son componentes esenciales en arquitecturas distribuidas, ya que permiten el desacoplamiento de diferentes servicios mediante la comunicación asíncrona.
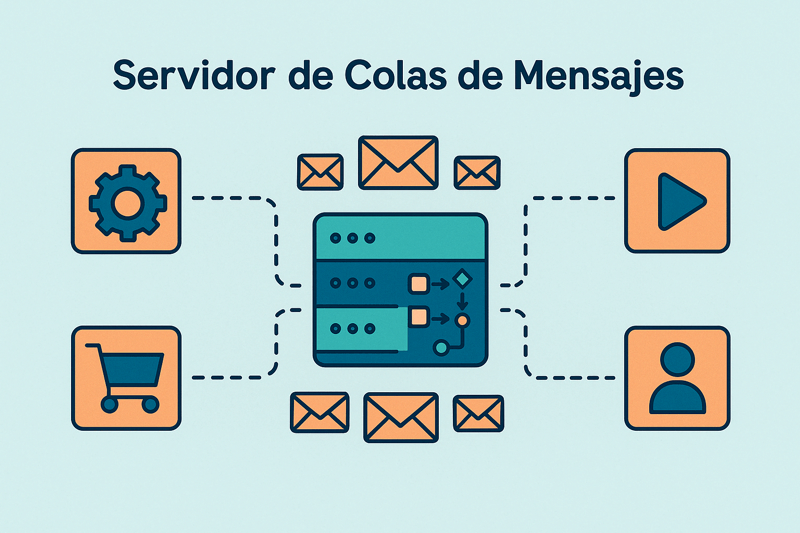
En lugar de que un servicio espere una respuesta inmediata de otro, envía un mensaje a la cola y continúa con sus tareas. El servicio receptor procesa el mensaje cuando tiene recursos disponibles. Esto es vital para tareas de procesamiento intensivo (como el procesamiento de imágenes o videos), flujos de eventos en tiempo real (como actualizaciones de noticias o feeds de redes sociales) o la integración con servicios externos (como el envío de correos electrónicos) sin bloquear la aplicación principal y mejorando la resiliencia.
Imagina el siguiente caso de uso: Cuando un usuario sube una foto a una red social, la aplicación principal puede enviar un mensaje a una cola. Un servicio separado (un «worker») toma ese mensaje de la cola, redimensiona la imagen, genera miniaturas y la guarda en el almacenamiento, sin que el usuario tenga que esperar a que todo este proceso termine para continuar navegando.
Tecnologías utilizadas:
- RabbitMQ: Un broker de mensajes de código abierto ampliamente utilizado, conocido por su confiabilidad y flexibilidad.
- Apache Kafka: Una plataforma de transmisión de eventos distribuida, diseñada para manejar flujos de datos de alta velocidad y gran volumen en tiempo real. Es ideal para construir pipelines de datos y aplicaciones de streaming.
- Amazon SQS (Simple Queue Service): Un servicio de colas de mensajes totalmente gestionado ofrecido por AWS, que permite desacoplar y escalar microservicios, sistemas distribuidos y aplicaciones sin servidor.
Servidores de Archivos y Objetos
En lugar de sobrecargar las bases de datos con el almacenamiento de archivos binarios (imágenes, videos, documentos, etc.), una infraestructura backend moderna delega esta responsabilidad a servidores de archivos u objetos.
Esto mejora significativamente el rendimiento de la base de datos, reduce los costos de almacenamiento y facilita la escalabilidad. Estos servidores están optimizados para almacenar y servir grandes cantidades de datos no estructurados.
Imagina el siguiente caso de uso: Una aplicación de almacenamiento de fotos como Google Photos utiliza servidores de objetos para almacenar las imágenes y videos de los usuarios. Estos servidores están diseñados para manejar petabytes de datos y ofrecer un acceso rápido a los archivos.
Tecnologías utilizadas:
Soluciones On-premise
- NFS (Network File System): Un protocolo de sistema de archivos distribuido que permite a los usuarios acceder a archivos a través de una red como si estuvieran en su sistema local.
- GlusterFS: Un sistema de archivos distribuido escalable que agrega múltiples recursos de almacenamiento en un único espacio de nombres global.
Soluciones Cloud:
- Amazon S3 (Simple Storage Service): Un servicio de almacenamiento de objetos altamente escalable, duradero y disponible en la nube de AWS.
- Google Cloud Storage: Un servicio de almacenamiento de objetos escalable y de alto rendimiento en la nube de Google Cloud Platform.
Servidores de Autenticación y Autorización
Aunque las funcionalidades de autenticación (verificar la identidad de un usuario) y autorización (determinar qué recursos puede acceder un usuario autenticado) pueden integrarse directamente en la aplicación principal, en sistemas más complejos y con mayores requisitos de seguridad, se externalizan a servidores especializados. Esto centraliza el control de identidad, mejora la seguridad y facilita la implementación de características avanzadas.
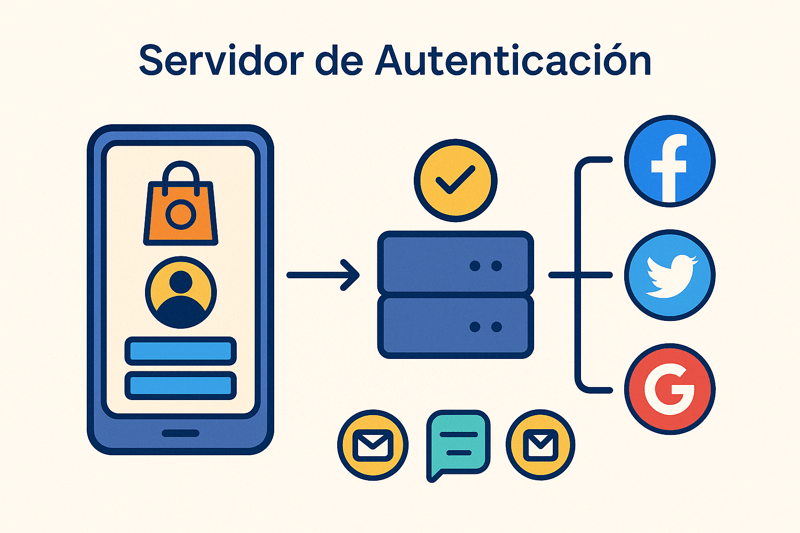
Un caso práctico es cuando una aplicación que permite el inicio de sesión con cuentas de redes sociales (federación de identidad) se beneficia de un servidor de autenticación especializado que maneja los protocolos de autenticación con diferentes proveedores.
Tecnologías utilizadas:
Keycloak: Una solución de código abierto para la gestión de identidades y el control de acceso. Soporta protocolos como OpenID Connect y SAML.
Auth0: Una plataforma de identidad como servicio (IDaaS) que proporciona autenticación y autorización para aplicaciones web, móviles y heredadas.
IdentityServer: Un framework de código abierto para ASP.NET Core que implementa los protocolos OpenID Connect y OAuth 2.0.
Cognito (en AWS): Un servicio de AWS que proporciona autenticación, autorización y administración de usuarios escalable para aplicaciones web y móviles.
La externalización permite aplicar federación (permitir a los usuarios iniciar sesión con credenciales de otros proveedores), SSO (Single Sign-On) (permitir a los usuarios iniciar sesión una vez y acceder a múltiples aplicaciones) y una mayor trazabilidad sobre quién accede a qué recursos y cuándo.
Servidores de logging, monitoreo y observabilidad
Para mantener la salud y el rendimiento de una infraestructura backend compleja, es crucial contar con servidores dedicados a la recolección y visualización de métricas y logs centralizados.
Estos servidores permiten a los equipos de desarrollo y operaciones trazar errores para identificar la causa raíz de los problemas, medir tiempos de respuesta para evaluar el rendimiento, detectar anomalías que puedan indicar problemas potenciales y generar alertas automáticas para responder proactivamente a incidentes.
Es muy habitual que un equipo de operaciones puede utilizar un panel de control (dashboard) para visualizar en tiempo real el uso de CPU y memoria de todos los servidores, la latencia de las API y las tasas de error. Si una métrica supera un umbral definido, se genera una alerta.
Tecnologías utilizadas:
Prometheus + Grafana: Prometheus es un sistema de monitoreo y alertas de código abierto que recolecta métricas de los sistemas. Grafana es una plataforma de visualización de datos que se integra perfectamente con Prometheus para crear dashboards informativos.
ELK (Elasticsearch + Logstash + Kibana): Un stack popular para la gestión y análisis de logs. Elasticsearch es un motor de búsqueda y análisis distribuido, Logstash es un pipeline de procesamiento de datos y Kibana es una herramienta de visualización para Elasticsearch.
Loki: Un sistema de consulta de logs inspirado en Prometheus, diseñado para ser rentable y fácil de operar.
Jaeger: Un sistema de tracing distribuido de código abierto utilizado para monitorear y solucionar problemas en arquitecturas de microservicios. Permite rastrear las solicitudes a medida que atraviesan diferentes servicios.
OpenTelemetry: Un proyecto de código abierto que proporciona APIs, SDKs, y herramientas para crear y gestionar datos de telemetría (métricas, logs y traces). Busca estandarizar la forma en que se genera y recolecta la observabilidad.
Diseñar una infraestructura backend eficaz no consiste solo en elegir el mejor lenguaje o framework, sino en orquestar adecuadamente todos los componentes que la conforman. Cada tipo de servidor cumple un propósito específico que, en conjunto, permite que una aplicación escale, responda con rapidez, sea tolerante a fallos y respete los principios de seguridad y observabilidad.
En la era de la computación en la nube, muchas de estas funciones se ofrecen como servicios gestionados, pero el conocimiento de su funcionamiento sigue siendo imprescindible para tomar decisiones arquitectónicas acertadas. Elegir cuándo y cómo incorporar servidores especializados —ya sea para bases de datos, colas, autenticación o logging— impacta directamente en la experiencia del usuario final y en los costos de operación.
Si este artículo te pareció útil, compártelo con tu equipo o en tus redes para que más profesionales puedan beneficiarse del contenido. ¡El conocimiento se construye mejor cuando se comparte!
Publicaciones que pueden interesarte:
El Patrón de Mensajería «Messages Queue» en una Arquitectura basada en Eventos
Técnica de almacenamiento en caché: Content Delivery Network (CDN)
Conceptos claves en el diseño y escalabilidad de Software