En este artículo abordaremos una breve descripción sobre los conceptos claves que se debe analizar en el diseño de sistema y escalabilidad del software.
Escalamiento Horizontal vs Escalamiento Vertical
La escalabilidad es la capacidad que tiene un sistema para soportar una mayor carga sin impactar en su funcionalidad. Un sistema puede ser escalado de dos maneras:
Escalamiento Vertical (Vertical Scaling) significa incrementar los recursos de un nodo específico. Por ejemplo, podrías agregar memoria adicional a un servidor para mejorar su capacidad de operación ante el incremento del tráfico de visitas.
Los recursos que podrías incrementar en un servidor serían la memoria RAM, procesador (CPU) y/o almacenamiento, según las necesidades de tu sistema.
Escalamiento Horizontal (Horizontal Scaling): significa incrementar el número de nodos. Por ejemplo, podrías agregar servidores adicionales, disminuyendo así la carga en cualquier servidor.
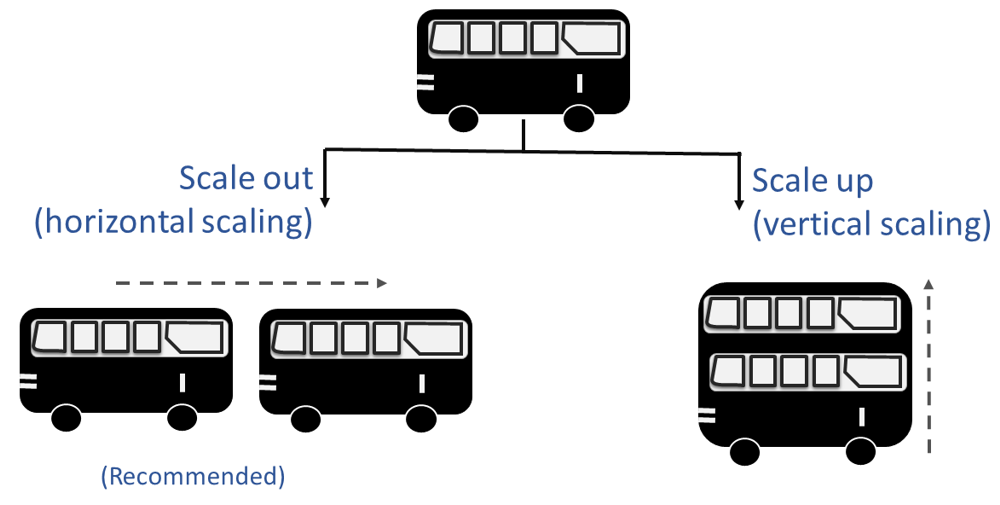
El escalamiento vertical es generalmente el más fácil de implementar, pero es limitado y poco eficiente en cuanto al presupuesto que debes destinar, teniendo en cuenta que posiblemente tu sistema tenga ventanas de tiempo con poca carga.
El escalamiento horizontal, se perfila cómo una alternativa eficiente, sin embargo, necesitarás realizar adaptaciones en tu sistema para trabajar el procesamiento y almacenamiento de una manera distribuida entre los nodos.
Balanceador de Carga (Load Balancer) & CDN
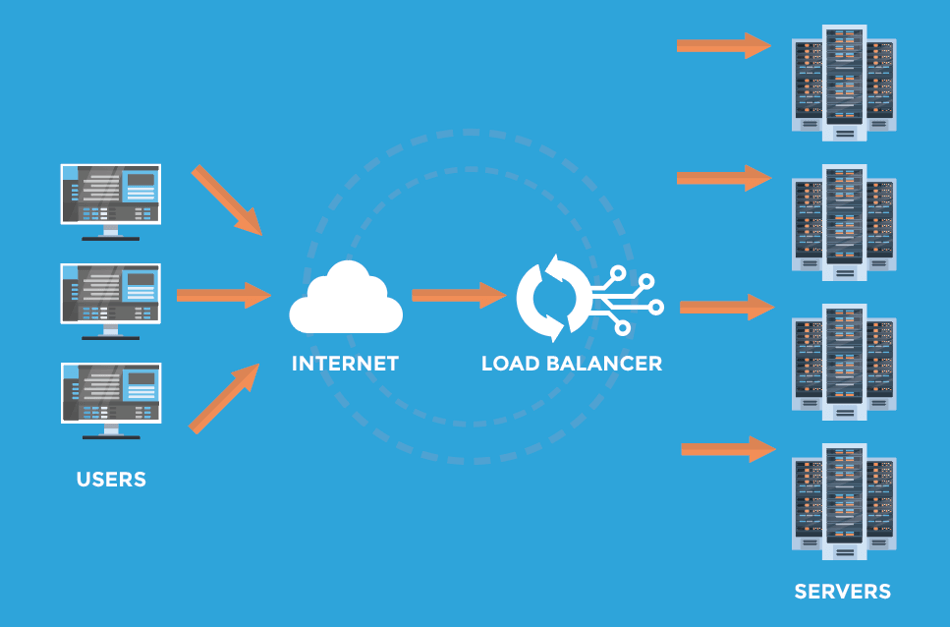
El balanceador de carga es un componente de la arquitectura de red que permite que un sistema distribuya la carga (tráfico de red entrante) de manera uniforme entre múltiples servidores, evitando que el sistema falle por la saturación en el consumo de recursos de un solo nodo.
Para implementar esta técnica se requiere construir una red de servidores clonados que tengan la misma aplicación ejecutandose y los mismos accesos a la fuente de datos.
Desnormalización de base de datos y NoSQL
A medida que un sistema crece, las consultas y joins a las base de datos relacionales pueden volverse muy lentas o presentar inconsistencias según el volumen de escritura o lectura de datos que tenga su sistema. Esto origina que las bases de datos relacionales, no sean una solución eficiente para determinados casos de uso.
La desnormalización, puede resultar para muchos ir en contra de los principios de diseño de una base de datos relacional debido a que debes agregar datos redudantes para acelerar los tiempos de lecturas a la base de datos. Es precisamente esta característica que incorporan las base de datos NoSQL, donde es muy común encontrar datos redudantes en los diferentes nodos de un cluster.
Por ejemplo, si necesitas desarrollar un sistema de análisis de monitoreo en tiempo real donde se realizan constantemente consultas de información, consultas cruzadas o joins para tablas con más de 1 millón de registros, esta operación podría convertirse en un cuello de botella. Al permitir la redundancia de datos (debidamente gobernada), no necesitarías realizar consultas cruzadas, la información la podrías servir directamente e incluso desde diferentes nodos.
Partición de Base de Datos (Database Sharding)
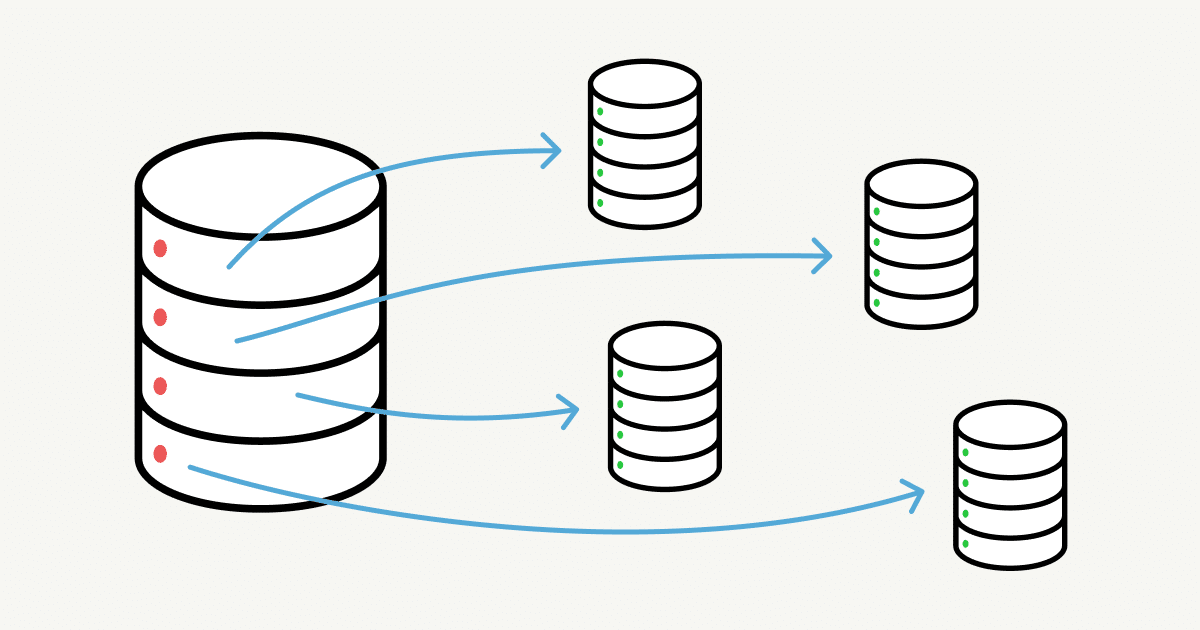
La técnica de database sharding, significa dividir los datos en varias máquinas (nodos), mediante un mecanismo que te permita determinar que datos están en cada máquina. Algunas estrategias conocidas para particionar datos son:
Partición Vertical (Vertical Partitioning): Es una estrategia de partición de datos por característica o dominio funcional. Si por ejemplo, estuvieras desarrollando una plataforma de comercio electrónico, podría tener una base de datos para todo lo relacionado al catálogo de productos, otra base de datos para todo lo relacionado a las ordenes de compra, y otra base de datos para la facturación o CRM. Esta técnica tiene una desventaja, porque una base de datos podría crecer demasiado, requeriendo volver a emplear una partición adicional.
Partición basado en llaves (Key-Based Partitioning): Esta estrategia tiene como objetivo distribuir los datos de manera uniforme entre diferentes particiones (nodos), lo que permite mejorar el rendimiento, la escalabilidad y el procesamiento paralelo. Por ejemplo, podrías particionar los datos de los perfiles de usuario de una red social, mediante su ID, es decir, los usuarios con ID 1 al 500,000 podrían estar en nodo 1, los usuarios con ID 500,001 al 1’000,000 podrían estar en el nodo 2 y así sucesivamente.
Partición basada en directorio (Directory-Based Partitioning): Esta técnica consiste en mantener una tabla de búsqueda sobre donde puede encontrar los datos, similar a cómo si tuvieras un directorio telefónico. Esta técnica puede tener algunas ventajas cómo tener un lugar donde empezar a buscar la información o donde definir algunas reglas o configuraciones que pueda requerir tu sistema, sin embargo también tiene algunos inconvenientes, cómo que pasaría si la tabla de búsqueda tuviera una falla, y además el acceso constante a esta tabla podría afectar el rendimiento. Tendrías que evaluar los escenarios, podrías emplear una copia de este directorio en memoria, sin embargo todo depende del caso de uso de tu proyecto, deberías evaluar que técnica te podría resultir más útil.
Caching
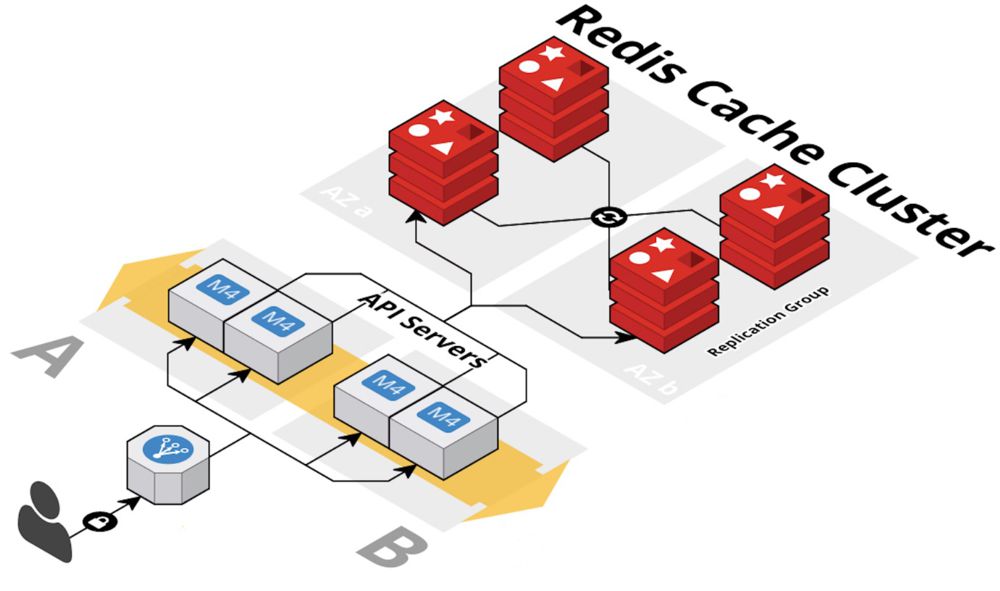
Una caché, es un componente que almacena información temporal que se utiliza para servir a solicitudes de una manera más rápida. Está caché generalmente almacena información mediante un formato Key-Value alojado en la memoria RAM del servidor, de esta manera tu caché tendrá un mejor tiempo de respuesta en comparación a la información que se almacena en disco, por lo tanto, este componente suele ubicarse entre la capa de aplicación y la base de datos. Para emplear esta técnica, deberás realizar adecuaciones en tu aplicación para almacenar el resultado de una consulta a la base de datos en la memoria caché, y mediante un mecanismo de expiración y/o actualización, podrías recuperar la información que constantemente tus usuarios necesitan, accediendo directamente a la caché (en memoria RAM) y no de la base de datos (en disco).
Procesos asincronos y colas
Habrán situaciones donde tu aplicación se tome más tiempo de lo habitual para procesar una información o ejecutar una serie de tareas continuas. Para estos casos donde se presenten operaciones lentas, una alternativa es utilizar procesos asincronos. De lo contrario, un usuario podría quedarse esperando y esperando a que se complete el proceso, originando una mala experiencia al usuario.
Por ejemplo, se te pide desarrollar un API OCR que reciba peticiones que traen consigo un documento (imagen o archivo PDF) al cual debas analizar, transformar y extraer su contenido y devolver algunos datos calculados en un formato JSON. En estos casos, este proceso podría tomar posiblemente más de 1 minuto en completarse según cómo esté diseñado dicho proceso. En estos casos, tu API podría recibir la información, crear una solicitud OCR, devolver un ID de dicha solicitud al usuario e indicarle que será notificado cuando se complete su proceso ó que pueda consultar su solicitud mediante el ID compartido utilizando otro endpoint del API. En este escenario, estás devolviendo una respuesta temprada al usuario, mientras el proceso OCR se esté ejecutando de manera asincrona.
Metricas de Red

Algunas de las más importantes métricas de red son:
Bandwith (Banda Ancha): Esta métrica se refiere a la capacidad o el rendimiento de una red de comunicación para transferir datos, por lo tanto podríamos decir que es la cantidad máxima de datos que se pueden transferir (a traves de la red) en una unidad de tiempo. Normalmente se expresa en bits por segundo ó en gigabytes por segundo, según la dimensión de tu aplicación.
Throughput (Rendimiento): Es la métrica que refleja la cantidad real de datos transferidos en determinado periodo de tiempo.
Latency (Latencia): Este indicador se refiere al tiempo que trascurre entre el inicio de una solicitud y la entrega de la respuesta. La latencia de una aplicación puede ser originada por el estado de la red, por un retraso en el procesamiento de la información que debe realizar el sistema, o por el retraso en el almacenamiento físico de la información en base de datos (a nivel de hardware).
Manejo de Fallas del Sistema

Debemos saber que cualquier componente del sistema puede fallar o presentar errores no identificados en la etapa de pruebas o incluso puede tratarse de errores humanos, por lo que necesitas tener un plan de acción ante estos eventos. Dependiendo de las características de tu sistema, es probable que puedas automatizar la recuperación del estado de la aplicación, sin embargo, pueden existir otros procedimientos manuales que deben tener asignado un responsable.
Disponibilidad y Fiabilidad
La disponibilidad es una métrica porcentual del tiempo que un sistema está operativo y accesible para los usuarios.
La fiabilidad es la capacidad que tiene un sistema para realizar de manera consistente y predecible las funciones previstas sin errores, ni fallas en un determinado periodo de tiempo.
Lecturas Intensas vs Escrituras Intensas

La lectura intensa (read-heavy) se refiere cuando una aplicación experimenta un volumen significamente mayor de operaciones de lectura o consultas de información.
La escritura intensa (write-heavy) se refiere cuando una aplicación experimenta un volumen significamente mayor de operaciones de inserción de información en la base de datos.
Ambos escenarios de alta concurrencia podrían afectar el rendimiento y disponibilidad de tu aplicación. Si tu sistema experimenta un escenario de escritura intensa, podrías considerar utilizar un sistema de colas de escritura para garantizar la secuencia y consistencia de las operaciones de escritura en base de datos. Si tu sistema experimenta un escenario de lectura intensa, podrías utilizar un sistema de caché. También deberías replantear el diseño de tu sistema para abordar de una manera más precisa las casuísticas que tuvieran.
Seguridad

No hay sistema perfecto, ni técnicas, ni decisiones técnicas que puedan garantizar que tu sistema no pueda ser afectado por una amenaza de seguridad. Por lo tanto, deberías de implementar métricas y herramientas para proteger tu sistema de software, la información que almacenas, y los accesos y niveles de permiso de los usuarios que utilizan tu sistema, entre otras vulnerabilidades potenciales. La seguridad es un aspecto crítico en cualquier diseño de software, para lo cual debes aplicar técnicas, principios y estrategias, cómo:
- Implementar una gestión de autenticación de usuarios
- Definir niveles de autorización y permisos para las cuentas de usuarios
- Aplicar técnicas de encriptación de datos sensibles
- Implementar procesos para verificación de alteración del código fuente (en producción)
- Emplear herramientas de monitoreo y alertas a nivel de red.
- Aplicar escaneos de red y de aplicación.
- Aplicar prácticas de auditoría a nivel de aplicación e infraestructura.
El diseño y escalabilidad de sistemas de software es proceso iterativo que requiere planificación, pruebas y refinamientos a medida que el software vaya evolucionando con nuevas características y creciendo por la demanda de nuevos usuarios. En el diseño de software, habrán buenas soluciones y malas soluciones. No hay una solución perfecta.
Publicaciones relacionadas:
Fuentes:
- Designing Data-Intensive Applications
- Craking the coding interview